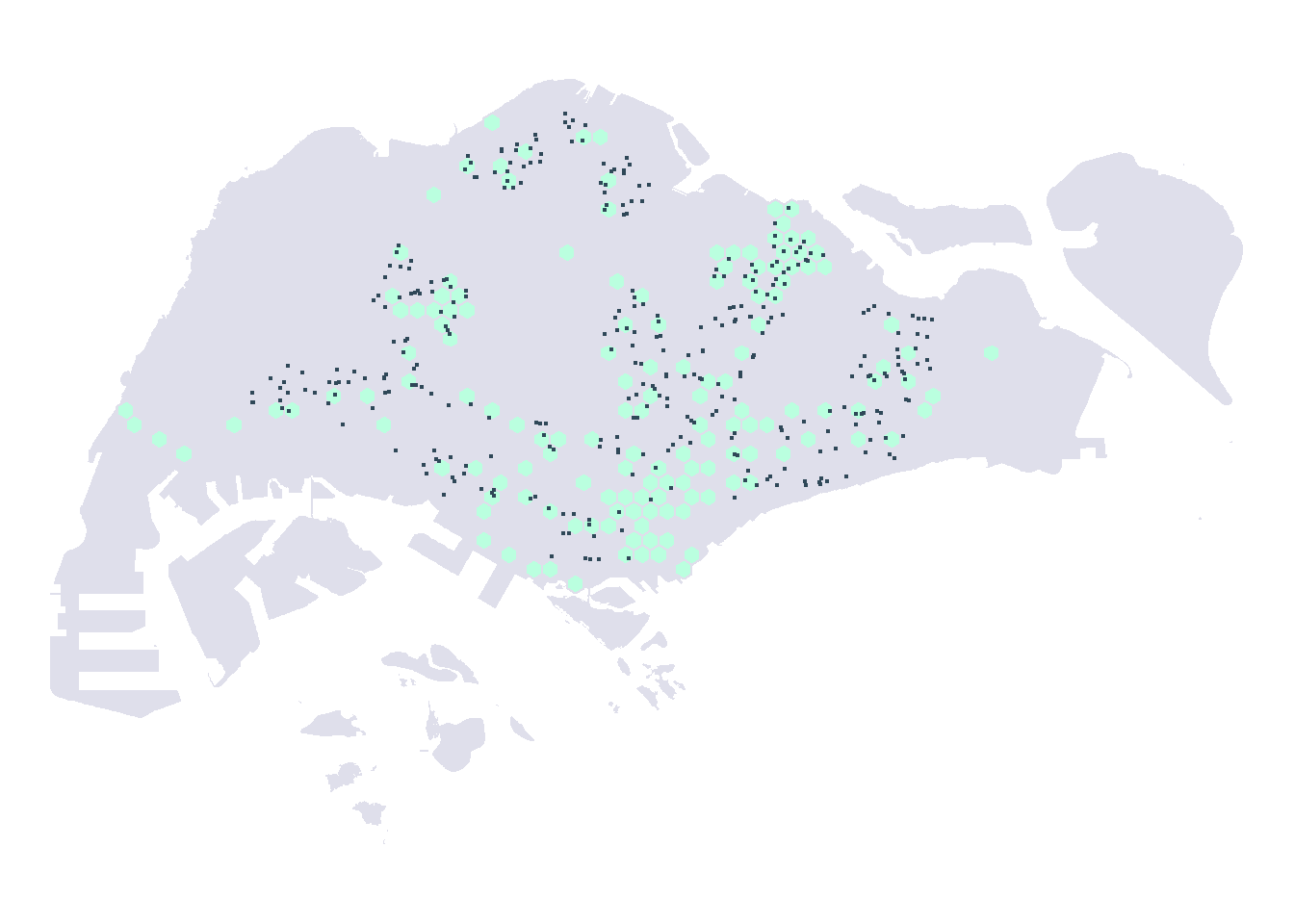
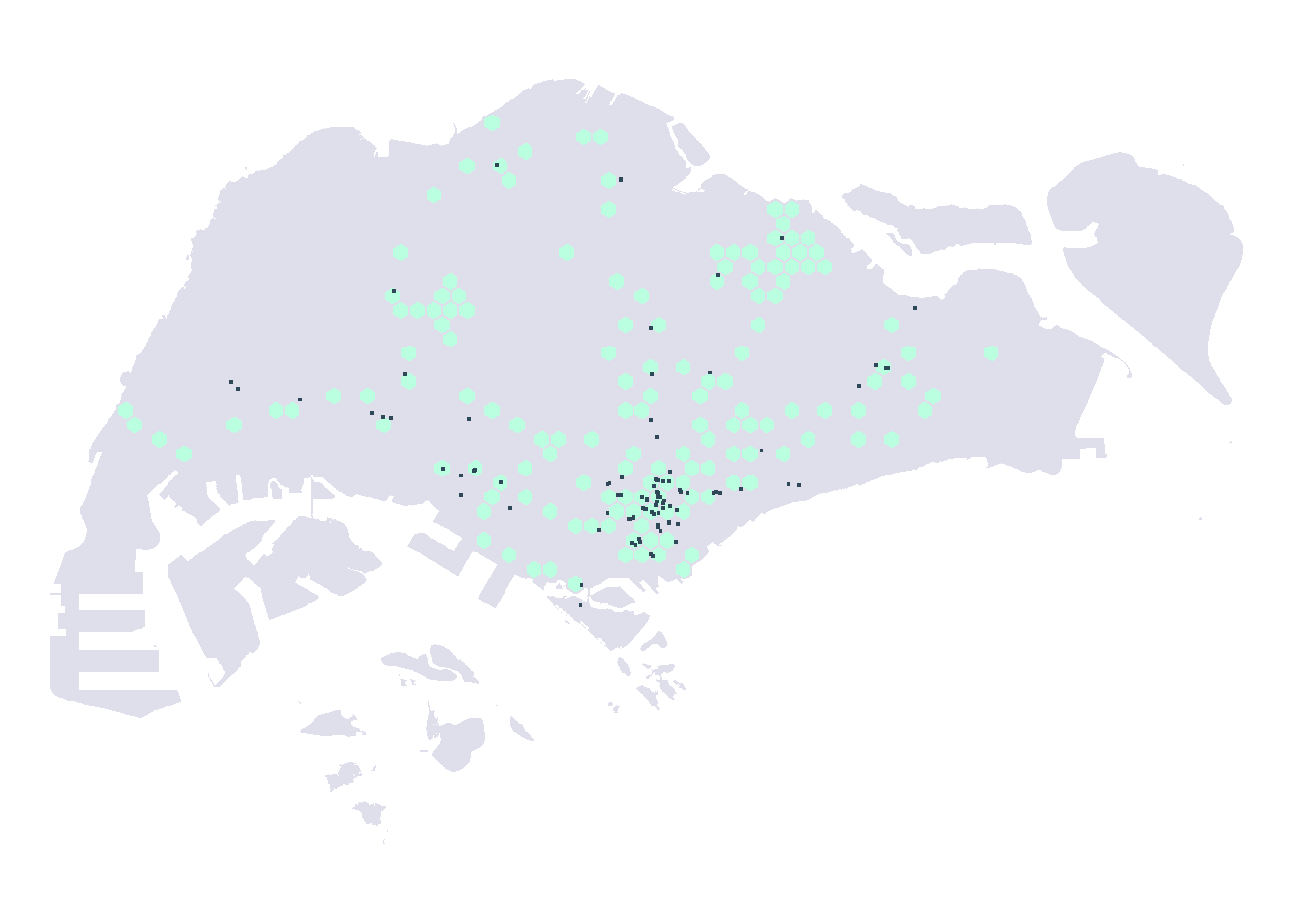
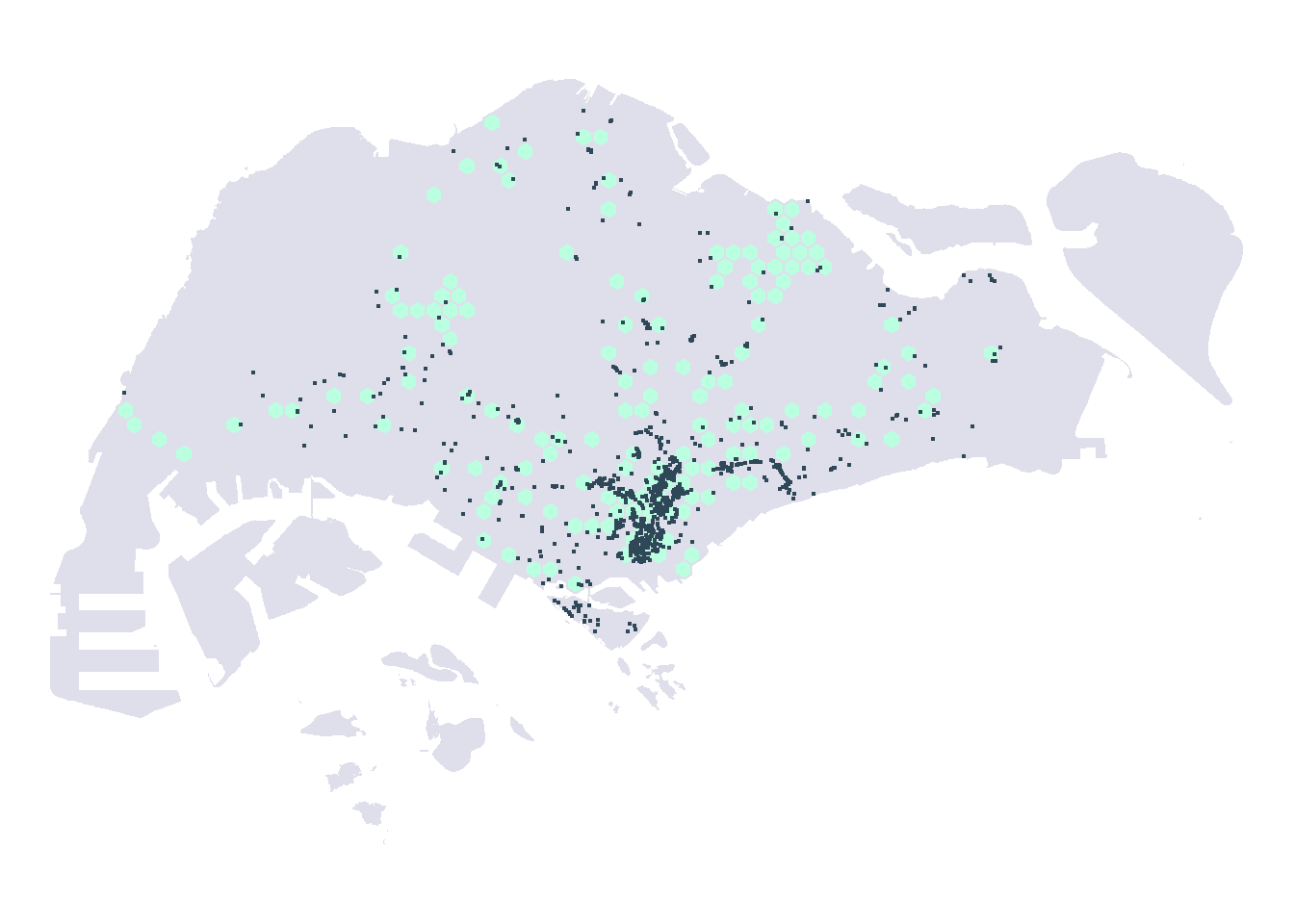
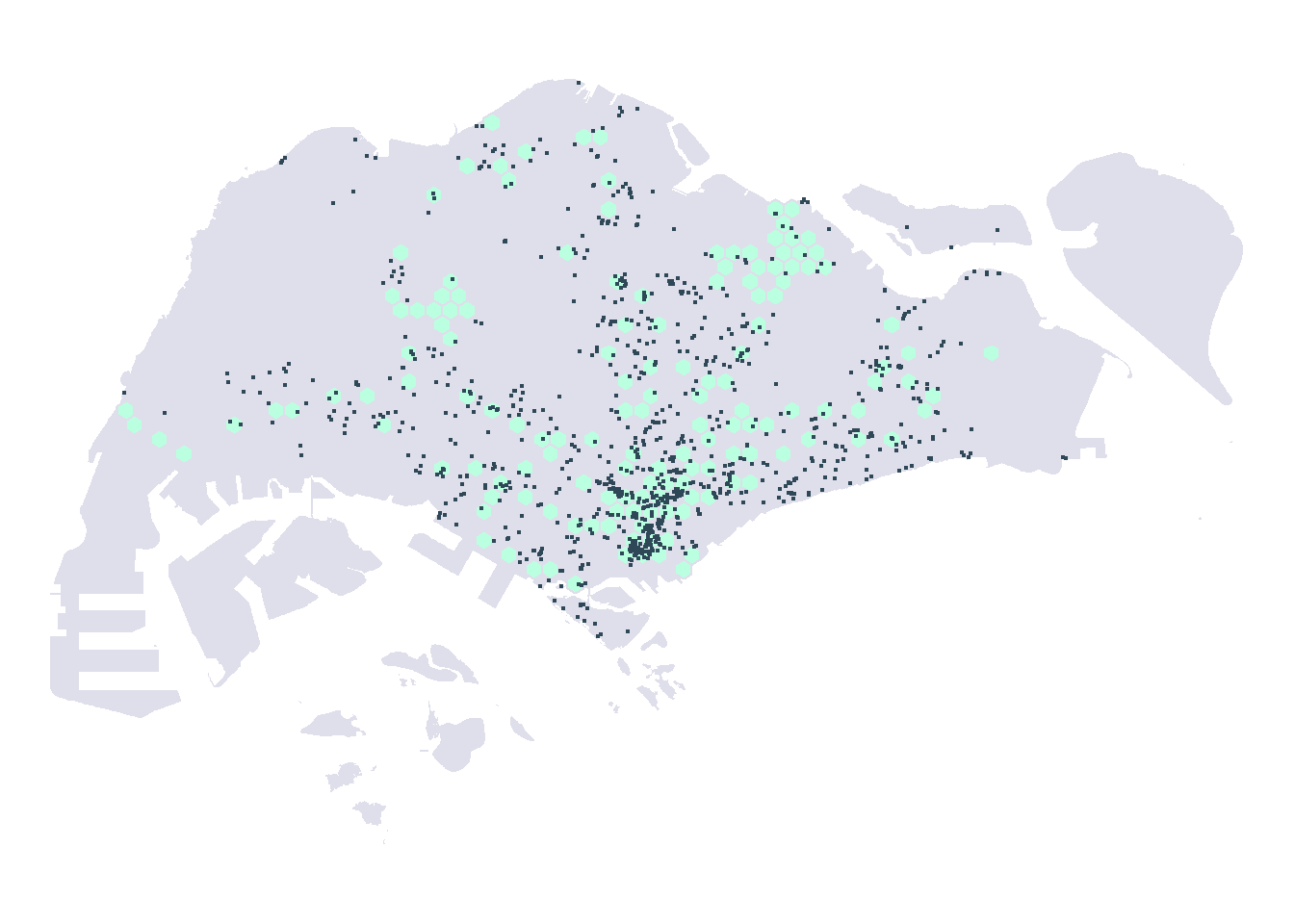
As city-wide urban infrastructure such as public buses, mass rapid transit, public utilities and roads become digital, the data sets obtained can be used for tracking movement patterns through space and time. This is particularly true with the recent trends in massive deployment of pervasive computing technologies such as GPS on vehicles and SMART cards used by public transport commuters.
Unfortunately, this explosive growth of geospatially-referenced data has far outpaced the planner’s ability to utilize and transform the data into insightful information. There has not been significant practice research carried out to show how these disparate data sources can be integrated, analysed, and modelled to support policy making decisions, and a general lack of practical research to show how geospatial data science and analysis (GDSA) can be used to support decision-making.
This study aims to demonstrate the potential value of GDSA to integrate publicly available data from multiple sources for building spatial interaction models to determine factors affecting urban mobility patterns in public bus transit.
2 Loading Required packages
The following packages are used in this exercise:
tmap for cartography
mapview for interactive map backgrouds & leaflet.providers for basemap customisation
sf and sp for geospatial data handling
stplanr for creating ‘desire lines’
tidyverse and reshape2 for aspatial data transformation
sfdep and spdep for computing spatial autocorrelation
Hmisc for summary statistics
kableExtra and DT for formatting of dataframes
ggplot2, patchwork and ggrain for visualising attributes
performance ang ggpubr for Spatial Interaction modeling
This study uses 2 aspatial datasets pertaining to Public Train Trips:
train, a dataset from LTA Datamall, Passenger Volume by Origin Destination Train Stations for October 2023.
train_codes, also from LTA Datamall, lists train station codes and names. This is used to assign MRT train station codes to the geospatial data set with train station locations.
train_oct23 is a tibble dataframe consisting of the following variables:
YEAR_MONTH: Month of data collection in YYYY-MM format
DAY_TYPE: Category of Day
TIME_PER_HOUR: Extracted hour of day
PT_TYPE: Public transport type
ORIGIN_PT_CODE: ID of Trip Origin Train Station
DESTINATION_PT_CODE: ID of Trip Destination Train Station
TOTAL_TRIPS: Sum of trips made per origin-Destination
Hmisc::describe(train_oct23)
train_oct23
7 Variables 800595 Observations
--------------------------------------------------------------------------------
YEAR_MONTH
n missing distinct value
800595 0 1 2023-10
Value 2023-10
Frequency 800595
Proportion 1
--------------------------------------------------------------------------------
DAY_TYPE
n missing distinct
800595 0 2
Value WEEKDAY WEEKENDS/HOLIDAY
Frequency 424314 376281
Proportion 0.53 0.47
--------------------------------------------------------------------------------
TIME_PER_HOUR
n missing distinct Info Mean Gmd .05 .10
800595 0 20 0.997 14.01 6.042 6 7
.25 .50 .75 .90 .95
10 14 18 21 22
Value 0 5 6 7 8 9 10 11 12 13 14
Frequency 4083 23741 37878 42772 43653 43289 43466 44412 45463 45298 44883
Proportion 0.005 0.030 0.047 0.053 0.055 0.054 0.054 0.055 0.057 0.057 0.056
Value 15 16 17 18 19 20 21 22 23
Frequency 45358 46141 47505 46815 44605 42622 41491 38360 28760
Proportion 0.057 0.058 0.059 0.058 0.056 0.053 0.052 0.048 0.036
For the frequency table, variable is rounded to the nearest 0
--------------------------------------------------------------------------------
PT_TYPE
n missing distinct value
800595 0 1 TRAIN
Value TRAIN
Frequency 800595
Proportion 1
--------------------------------------------------------------------------------
ORIGIN_PT_CODE
n missing distinct
800595 0 171
lowest : BP10 BP11 BP12 BP13 BP2 , highest: TE4 TE5 TE6 TE7 TE8
--------------------------------------------------------------------------------
DESTINATION_PT_CODE
n missing distinct
800595 0 171
lowest : BP10 BP11 BP12 BP13 BP2 , highest: TE4 TE5 TE6 TE7 TE8
--------------------------------------------------------------------------------
TOTAL_TRIPS
n missing distinct Info Mean Gmd .05 .10
800595 0 4672 0.998 104 171.3 1 1
.25 .50 .75 .90 .95
4 15 60 214 455
lowest : 1 2 3 4 5, highest: 16799 17670 18763 19585 21050
--------------------------------------------------------------------------------
From the summary statistics above, we can derive that:
There are 800,959 Origin-Destination (OD) trips made in October 2023
Data is collected for 24 hours, starting from 0 Hrs to 23 Hrs in TIME_PER_HOUR
The highest number of trips for an OD route is 21,050, while the 95th Percentile is only 455. This suggests a highly right-skewed distribution, with particularly busy routes.
As we are interested in studying the passenger flows for peak hour periods only, the number of trips are calculated for each period as defined below:
Peak Period
Tap in Time (hr)
Weekday Morning
6 - 9
Weekday Evening
17 - 20
Weekend/PH Morning
11 - 14
Weekend/PH Evening
16 - 19
The dataframe now shows the traffic volume by peak period for each Origin-Destination route:
code block
train_od <- train_oct23 %>%# Categorize trips under period based on day and timeframemutate(period =ifelse(DAY_TYPE =="WEEKDAY"& TIME_PER_HOUR >=6& TIME_PER_HOUR <=9, "Weekday morning peak",ifelse(DAY_TYPE =="WEEKDAY"& TIME_PER_HOUR >=17& TIME_PER_HOUR <=20,"Weekday evening peak",ifelse(DAY_TYPE =="WEEKENDS/HOLIDAY"& TIME_PER_HOUR >=11& TIME_PER_HOUR <=14,"Weekend/PH morning peak",ifelse(DAY_TYPE =="WEEKENDS/HOLIDAY"& TIME_PER_HOUR >=16& TIME_PER_HOUR <=19,"Weekend/PH evening peak","Others")))) ) %>%# Only retain needed periods for analysisfilter( period !="Others" ) %>%# compute number of trips per origin busstop per month for each periodgroup_by( ORIGIN_PT_CODE, DESTINATION_PT_CODE, period ) %>%summarise(num_trips =sum(TOTAL_TRIPS) ) %>%# change all column names to lowercaserename_with( tolower, everything() ) %>%ungroup()
There are several instances where ORIGIN_PT_CODE and DESTINATION_PT_CODE are not composite codes, representing MRT Stations that are interchanges with multiple station lines. For the purpose of this investigation, only a single station code is required.
code block
train_od <- train_od %>%separate_wider_delim(origin_pt_code,delim ="/", names =c("origin_station_code", "unused_origin"),# to capture first station for those without multiplestoo_few ="align_start",# to remove any other unused station columns for 3 or moretoo_many ="drop" ) %>%separate_wider_delim(destination_pt_code,delim ="/", names =c("dest_station_code", "unused_dest"),too_few ="align_start",too_many ="drop" ) %>%select( origin_station_code, dest_station_code, period, num_trips )DT::datatable(head(train_od,20))
This dataset lists train station codes and names. It is used to join with the geospatial dataset for station identification.
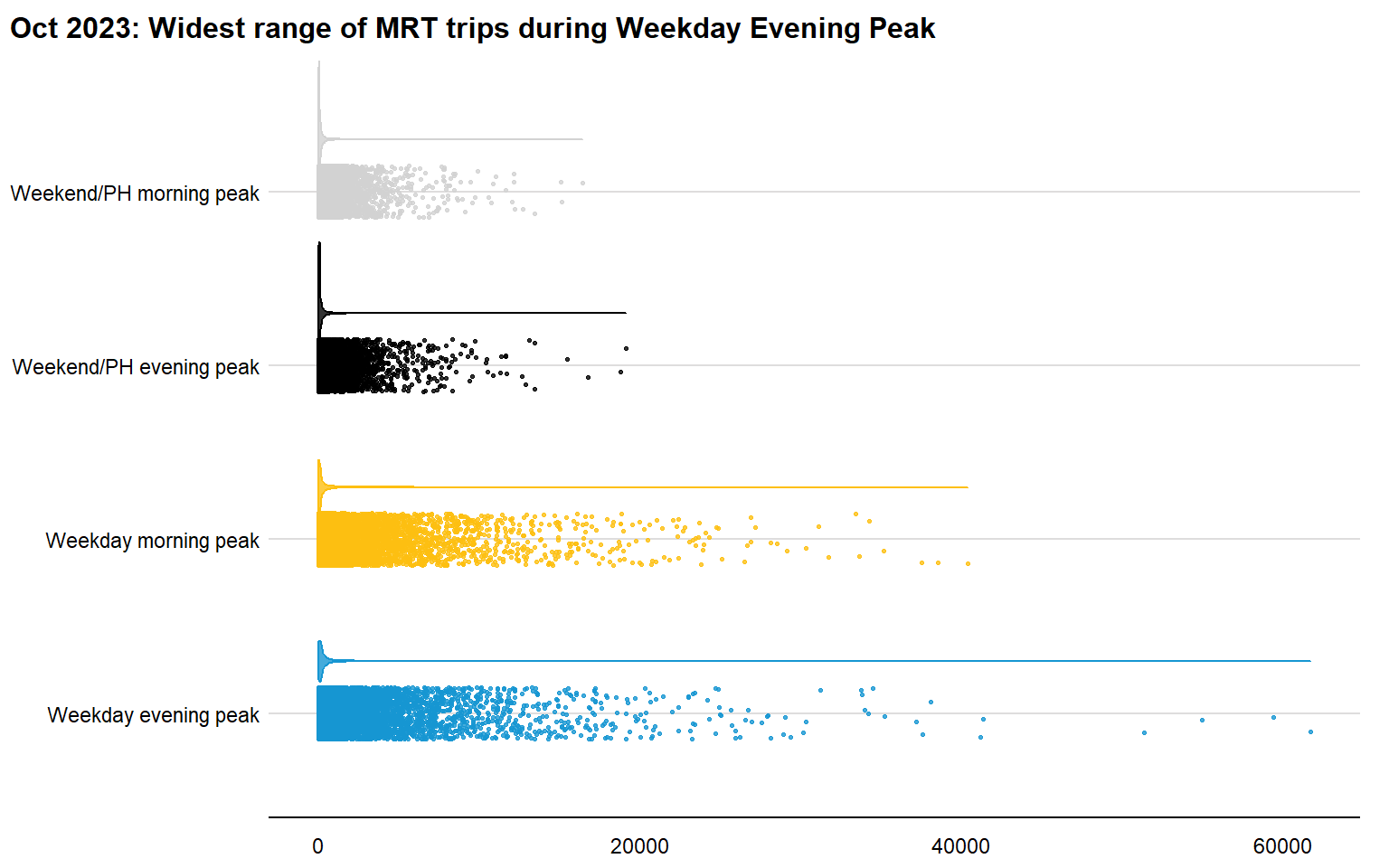
The density plot reveals a highly right-skewed distribution for all trips, especially during weekday evening peak periods. This could point towards congested MRT train stations, and would be useful to analyse further to determine the possible factors leading to this high passenger volume.
The OD data for weekday evening peak periods will thus be the focus of the study, and data is extracted using the following code chunk:
The following geospatial dataframes are used for this exercise:
train_station, the location of train stations (RapidTransitSystemStation) from LTA Datamall
Business, entertn, fnb, finserv, recreation and retail, geospatial data sets of the locations of business establishments, entertainments, food and beverage outlets, financial centres, leisure and recreation centres, retail and services stores/outlets compiled for urban mobility studies
mpsz, masterplan boundary 2019
4.2 Preparing Geospatial Files: train station
As the files are all based on Singapore Maps, they are in SVY21 coordinate reference system (CRS) and projected in ESPG code 3414 using st_transform()
Reading layer `RapidTransitSystemStation' from data source
`C:\haileycsy\ISSS624-AGA\Take-home_Ex\the2\data\geospatial'
using driver `ESRI Shapefile'
Simple feature collection with 220 features and 4 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 6068.209 ymin: 27478.44 xmax: 45377.5 ymax: 47913.58
Projected CRS: SVY21
Dataset limitations
train_station only lists the Type of station (MRT or LRT), Station name and geolocation of each station. There is no station code to join with the aspatial dataset. Thus, the use of train_codes is needed to assign a unique train code identifier to each station
There are only 203 Station codes in train_codes, compared to 220 entries in train_station. There may be duplicated station names, which needs further investigation.
GDAL Message 1: Non closed ring detected – This warning message was received when loading in the geospatial layer. This means that there are polygons that are not closed (starting and ending points are not joined). There is a need for further geospatial data wrangling to rectify this.
Reading layer `MPSZ-2019' from data source
`C:\haileycsy\ISSS624-AGA\Take-home_Ex\the2\data\geospatial'
using driver `ESRI Shapefile'
Simple feature collection with 332 features and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 103.6057 ymin: 1.158699 xmax: 104.0885 ymax: 1.470775
Geodetic CRS: WGS 84
Checking for duplicated station entires in train_station:
train_duplicates <- train_station %>%# remove geometry layerst_set_geometry(NULL) %>%group_by(TYP_CD_DES, STN_NAM_DE ) %>%# count number of rows per train stationsummarise(count =n() ) %>%ungroup() %>%# retrieve stations with more than single rowfilter(count >1)DT::datatable(train_duplicates)
The code above reveals that there are several entries for the stations above in train_station. This may be due to the fact that some stations are interchanges and have multiple train lines. However, there is no way to differentiate this without station code, and this study will assume that the location of these stations are within the same boundary anyway. Only one geospatial entry per station is selected using slice():
As train_station does not have station codes that may be joined to the OD dataset for analysis, it is joined to train_codes by train station name. However, the station names in train_codes are in lowercase and without the suffix “MRT STATION” in the station names – there is thus an extra layer of data wrangling to be done before joining.
train_codes_new <- train_codes %>%# Assign suffix to train station names and change to upper casemutate(station_name =ifelse(type =="MRT", paste0(toupper(mrt_station_english), " MRT STATION"),paste0(toupper(mrt_station_english), " LRT STATION")) )
The code chunk below assigns train station code to the geospatial layer to identify each station by code.
As these are mainly train depots that are not identified by code and irrelvant to analysis of OD flows, these are removed from the dataset and saved as a new file, train_station_list:
From the mapview above, the current simple features dataframe only shows the train stations as points on the map, which not suitable for understanding commuter flows between areas. In urban transportation planning, Traffic Analysis Zones (TAZ) are the basic units of spatial areas delineated to tabulate traffic-related models.
The following code chunks create a hexagonal grid frame spanning 750m between edges for each hexagon:
# create hexagon frametrain_hex <-st_make_grid( train_station_valid, # for hexagonal cells, cellsize = the distance between opposite edgescellsize =750, square =FALSE ) %>%st_sf() %>%rowid_to_column("hex_id")
This creates a hexagonal grid over the entire area:
code block
tmap_mode("plot")qtm(train_hex)
# join to train station namestrain_stops <-st_join( train_station_valid, train_hex,join = st_intersects ) %>%st_set_geometry(NULL) %>%group_by(stn_code) %>%summarise(# Ensure that each station gets assigned to a single hex_idhex_id =first(hex_id) ) %>%ungroup() %>%group_by(hex_id) %>%summarise(station_count =n(),station_codes =str_c(stn_code, collapse =","), ) %>%ungroup()
# Get hexagons with at least one station train_hex_filtered <- train_hex_final %>%filter(station_count >0)tmap_mode("view")tm_basemap("CartoDB.Positron") +tm_shape(train_hex_filtered) +tm_fill(col ="station_count",palette ="-RdYlGn",style ="cont",id ="hex_id",popup.vars =c("No. of Train Stations: "="station_count","Train station codes: "="station_codes"),title =" " ) +tm_layout(# Set legend.show to FALSE to hide the legendlegend.show =FALSE )
5Which trips are the most congested on Weekday Evening Peaks?
We seek to understand the inter-zone trip volume per TAZ, to understand which routes are the most popular during weekday evening peak periods.
5.1 Preparing Origin-Destination flow data
The following steps are done to prepare O-D flow dataframes at hexagon level:
station_by_hex <- train_hex_final %>%select( hex_id, station_codes ) %>%st_drop_geometry() %>%# create separate rows for each hex_id - station_code pairseparate_rows(station_codes, sep ="," ) %>%# drop any hexagon without stationsfilter(station_codes !=0)
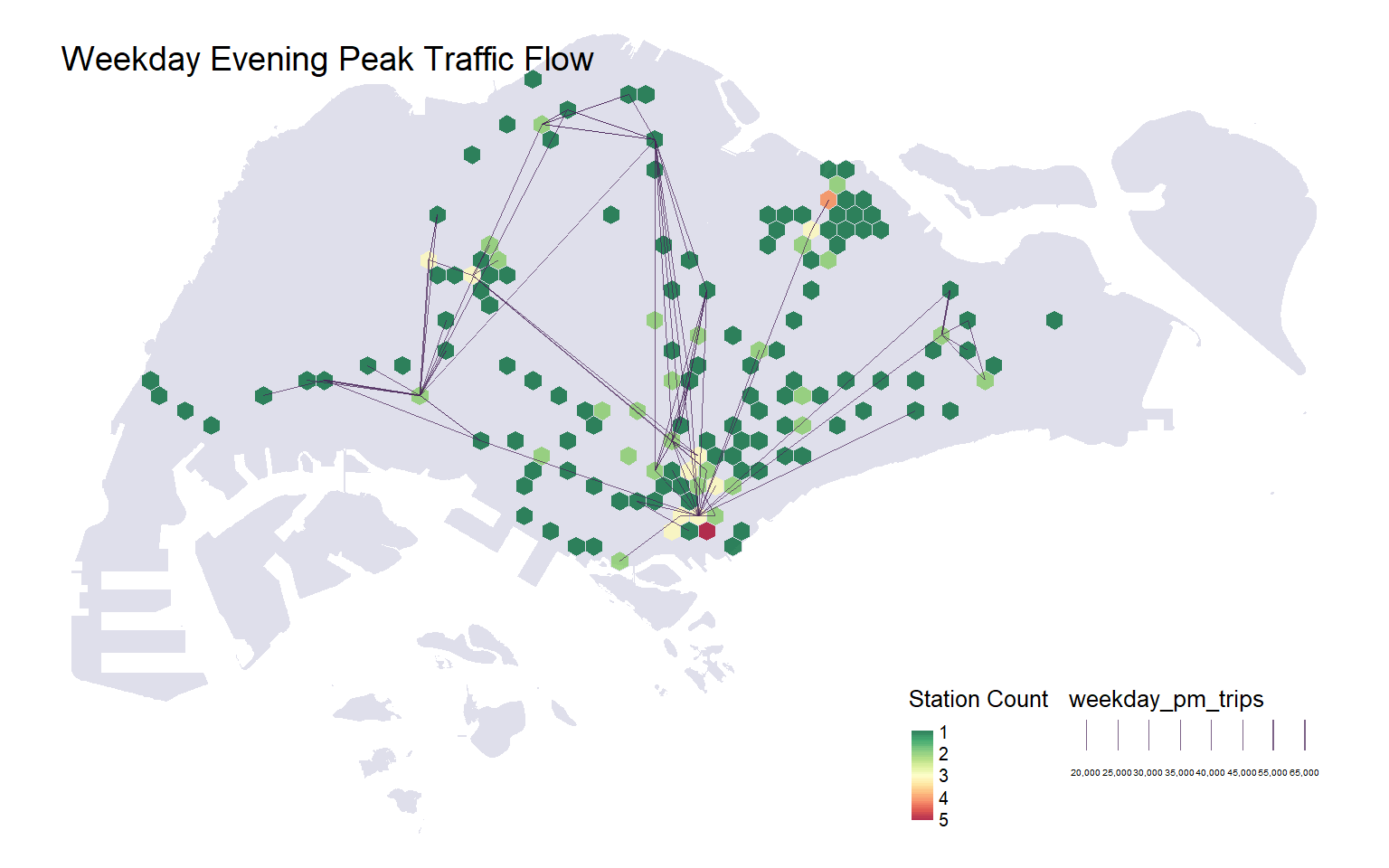
The animated O-D map shows that the flows with trip count < 10,000 is too dense for effective visualisation. As the number of trips increases, we also observe a slight concentration of flow lines within the Central/CBD district. To investigate this further, we focus on looking at the most popular O-D passenger flows for Weekday PM trips > 20,000:
A higher train station density in TAZs does not correlate to higher traffic. This is possibly due to the fact that a single station may encompass multiple lines (for instance, TAZ #1074 has the highest station density with 5 station codes, but this only corresponds to 3 stations: Marina Bay, Downtown & Shenton Way)
There are several TAZs with more flowlines, that are scattered across the country. This is suggestive of either being a key origin or destination zone for Weekday evenings. Namely:
TAZ #1058 (Telok ayer and Raffles Place MRT Stations)
TAZ #534 (Jurong East MRT Station)
TAZ #988 (Yishun MRT Station)
There are also TAZs with fewer but thicker flowlines, indicating highly popular origin or destination train stations, that are likely to be congested during Weekday evening peak periods. These are:
TAZ #1544 (Pasir Ris MRT Station)
TAZ #1028 (Novena MRT Station)
TAZ #774 (Woodlands MRT Station)
TAZ #573 (Yew Tee MRT Station)
Top 15 O-D flows by number of trips during Weekday Evening Peak Period:
The table above reveals that Jurong East MRT Station is the busiest origin station, with top OD trips originating from there. Only 2 TAZs occurred multiple times as top destination stations: Boon Lay and Newton MRT Stations. The fact that these stations are not in the city centre is slightly surprising, as one would assume that the busiest origin station would be in the CBD area where people would be commuting from after work.
Further analysis is conducted by using Spatial Interaction Models (SIMs) to determine factors explaining flow density between these TAZs.
6What makes these trip origins and destinations so popular?
To understand the factors affecting MRT passenger flows during weekday evening peak periods, we calibrate Spatial Interactive Models using a variety of factors as independent variables \(X\) and dependent variable total number of trips \(Y\). These factors can reveal propulsive or attractive qualities origin and destination zones respectively.
%%{
init: {
'theme': 'base',
'themeVariables': {
'primaryColor': '#ACAEDA',
'primaryTextColor': '#371F49',
'primaryBorderColor': '#3d7670',
'lineColor': '#371F49',
'secondaryColor': '#3d7670',
'tertiaryColor': '#371F49'
}
}
}%%
flowchart LR
L{fa:fa-moon \nWeekday \nEvening} -.- A{fa:fa-train-subway \nTrain Trips} --> B(Origin)
A --> C(Destination) -.- E[fa:fa-magnet \nAttractive \nfactors]
B -.- D[fa:fa-angles-right \nPropulsive \nfactors] --- O[fa:fa-ruler-horizontal Distance]
D --- F[fa:fa-house-user Residential density]
D --- G[fa:fa-briefcase Business]
D --- H[fa:fa-school Schools]
E --- I[fa:fa-dumbbell Recreation]
E --- J[fa:fa-burger Food & Beverage]
E --- K[fa:fa-cart-shopping Retail facilities]
E --- M[fa:fa-film Entertainment]
E --- N[fa:fa-ruler-horizontal Distance]
6.1 Attractive & Propulsive Factors
The factors listed above are computed at TAZ level for Spatial Interaction Modelling.
6.1.1 Distance
Computing the distance between Traffic analysis zones at a hexagonal level requires the computation of a distance matrix. This is a table that shows the Euclidean distance between each pair of locations, and is computed using the following steps:
The hexagon TAZ layer, train_hex_filtered, is a Simple Features dataframe. We first convert it to a SpatialPolygonsDataFrame using as_spatial() function
# convert to SpatialPolygonsDataFrametrain_hex_sf <-as_Spatial(train_hex_filtered)
# compute distance between hexagonsdist <-spDists(train_hex_sf, longlat =FALSE)head(dist, n=c(10, 10))
The resultant matrix has numbers as row and column headers, representing the hexagon pairs. To make this information more usable for analysis, we want to replace this with TAZ hexagon ids instead.
# Create a list of hex idshex_names <- train_hex_filtered$hex_id# Attach hex ids to row and column variables in distcolnames(dist) <-paste0(hex_names)rownames(dist) <-paste0(hex_names)head(dist, n=c(10, 10))
dist now has row and column headers as hex_id, identifying which TAZs the distance belongs to. However, the matrix has repeated information, and needs to be in an O-D format for geospatial modelling. The melt() function from package reshape2 is used for this.
The inter-zonal distance is computed between hexagon centroids. The same hexagon will thus have an inter-zonal difference of 0 to itself, but this is misrepresenative of intra-zonal difference. To rectify this, we append a constant value that is less than the minimum inter-zonal difference to all ‘0’ values.
origin_hex dest_hex distance
Min. : 23 Min. : 23 Min. : 750
1st Qu.: 796 1st Qu.: 796 1st Qu.: 6666
Median :1048 Median :1048 Median :10633
Mean :1016 Mean :1016 Mean :11210
3rd Qu.:1258 3rd Qu.:1258 3rd Qu.:15056
Max. :1741 Max. :1741 Max. :39086
The minimum distance is 750m – this represents the distance between the centre of a hexgon to the centre of an adjacent hexagon. We thus set the intra-zonal distance to 200 using an ifelse9) statement:
# If distance = 0, set to 200, else remain as isdistPair$distance <-ifelse(distPair$distance ==0,200, distPair$distance)summary(distPair)
origin_hex dest_hex distance
Min. : 23 Min. : 23 Min. : 200
1st Qu.: 796 1st Qu.: 796 1st Qu.: 6538
Median :1048 Median :1048 Median :10633
Mean :1016 Mean :1016 Mean :11138
3rd Qu.:1258 3rd Qu.:1258 3rd Qu.:15000
Max. :1741 Max. :1741 Max. :39086
The minimum distance is now set at 200m .
origin_hex and dest_hex represent unique areas, and are set to factor data types instead of integers:
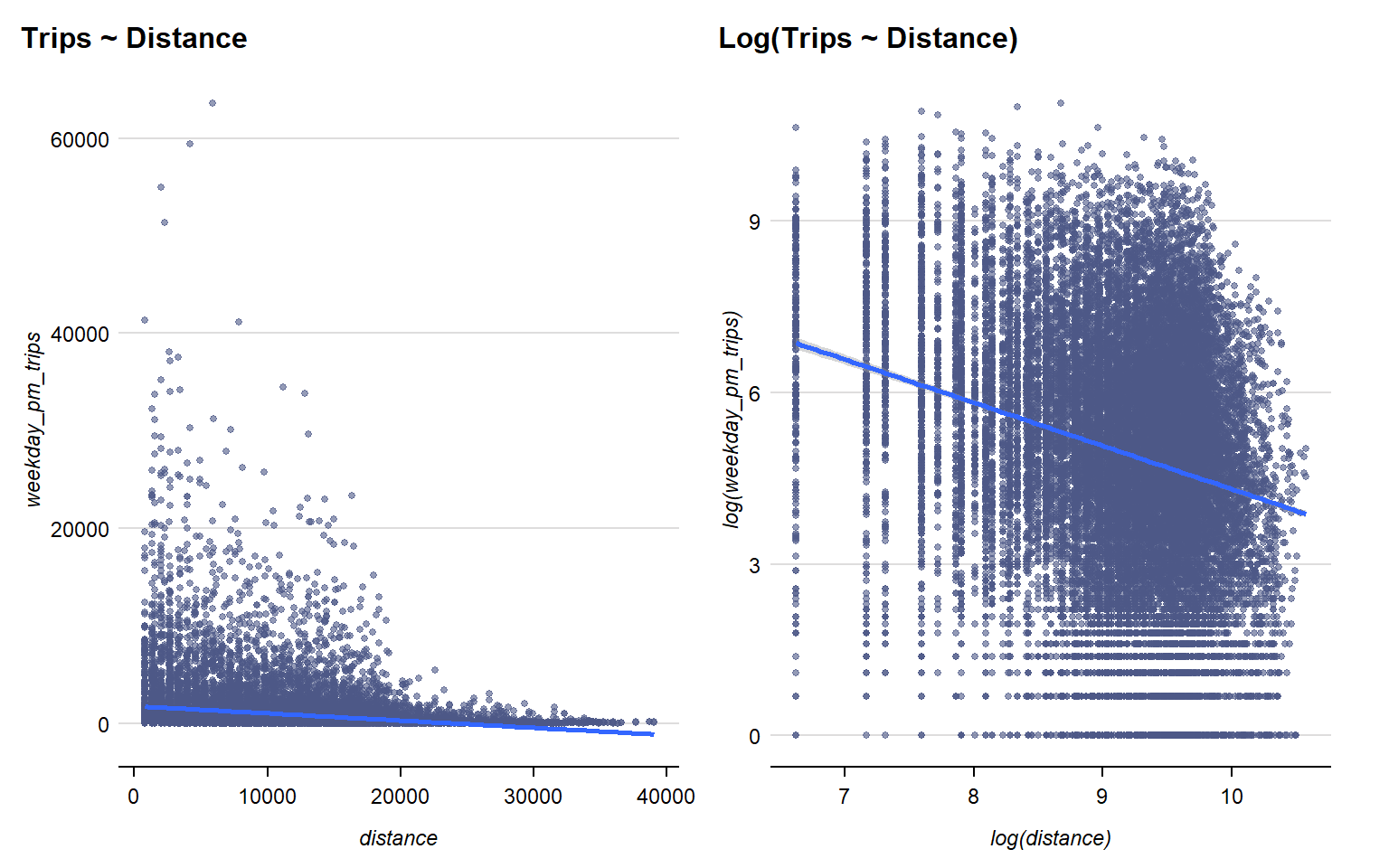
From the plots above, there is no obvious linear trend when using absolute figures. Using log transformed values, on the other hand, revealed an inverse relationship between higher number of trips and further distance.
6.1.3How is the number of trips correlated to other factors?
To determine factors that influence the movement of people between TAZ, we look at how flow data is related to propulsive and attractive attributes of the origin ans destination areas.
Propulsive attributes refer to factors that encourage or drive movement from one location to another and are associated with the origin of the journey, representing conditions that “push” or “propel” entities away from their current location
Attractive attributes are factors that pull or attract entities toward a specific location. These are associated with the destination and represent conditions that make a location appealing
As the flow data is based on weekday evening peak hours, propulsion is likely to be related to work, schools, or home (perhaps many people work from home). As such, number of businesses, number of schools and residential density per TAZ is computed as propulsive Attributes. On the other hand, leisure, food or shopping could be appealing at the end of a workday, and these are taken as attractive attributes.
These attributes are added to the flow data from the following sources:
The resultant dataframe is a simple features dataframe with point locations of business offices in Singapore. As this is not useful as point locations, we compute the number of offices per TAZ
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 0.000 0.000 3.416 1.000 135.000
schools is an aspatial dataframe with longitude and latitude data. This is imported and transformed into a Simple feature point layer based on SVY21 coordinate reference system (CRS).
schools <-read_csv("data/aspatial/schools.csv")
There are 40 columns in schools, but we only require a few variables. These are renamed and selected, and the data is transformed into a Simple Features Dataframe:
hdb is a geocoded list of HDB properties in Singapore, with information such as:
blk_no & street: Address of the HDB Property
max_floor_lvl & year_completed: Characteristics of the HDB building, indicative of height and age
residential, commercial, market_hawker, miscellaneous, multistorey_carpark & precinct_pavilion , a series of boolean columns indicating if the HDB Property has the facilities
bldg_contract_town: A code indicating HDB town
total_dwelling_units: Number of units in the block
xx_sold & xx_rental: multiple columns indicating number of units sold and rented per type
lat & lng: Geocoded lattitude and longitudinal data pertaining to HDB location
SUBZONE: Subzone information
hdb contains many variables, but only a few are useful for this exercise. The following code performs the following actions:
lng and lat are renamed for easier conversion
Filter only residential HDB properties
Select only relevant columns for analysis
hdb <- hdb %>%rename(longitude = lng,latitude = lat ) %>%filter(residential =="Y") %>%select( blk_no, street, postal, total_dwelling_units, longitude, latitude )
hdb is an aspatial dataframe, with longitude and latitude columns as variables. These are used to transform it into a simple feature layer to join at hexagon level using st_as_sf() function.
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.00 9.50 20.00 25.26 39.00 77.00
6.2 Preparing Modeling data by flow origin and destination
The following code chunks select attributes relevant to origin (propulsive factors) and destination (attractive factors) for Spatial Interaction Modelling.
origin_hex dest_hex trips trips_quantile
237 : 151 320 : 151 Min. : 1.0 < 50 :6373
320 : 151 353 : 151 1st Qu.: 36.0 100 ~ 250 :3644
353 : 151 436 : 151 Median : 161.0 1000 ~ 5000:3121
436 : 151 534 : 151 Mean : 945.7 250 ~ 500 :2762
534 : 151 637 : 151 3rd Qu.: 648.8 < 100 :2518
637 : 151 648 : 151 Max. :63626.0 500 ~ 1000 :2213
(Other):20692 (Other):20692 (Other) : 967
flowNoIntra offset distance origin_hdb
Min. : 1.0 Min. :1 Min. : 750 Min. : 0.00
1st Qu.: 36.0 1st Qu.:1 1st Qu.: 6495 1st Qu.: 0.00
Median : 161.0 Median :1 Median :10500 Median :13.00
Mean : 945.7 Mean :1 Mean :11059 Mean :19.38
3rd Qu.: 648.8 3rd Qu.:1 3rd Qu.:14981 3rd Qu.:34.00
Max. :63626.0 Max. :1 Max. :39086 Max. :77.00
origin_offices origin_schools dest_hdb dest_entertn
Min. : 0.00 Min. : 0.00 Min. : 0.00 Min. : 0.000
1st Qu.: 0.00 1st Qu.: 0.00 1st Qu.: 0.00 1st Qu.: 0.000
Median : 0.00 Median : 0.00 Median :14.00 Median : 0.000
Mean : 68.94 Mean : 22.75 Mean :19.72 Mean : 4.338
3rd Qu.: 53.00 3rd Qu.: 33.00 3rd Qu.:34.00 3rd Qu.: 0.000
Max. :2295.00 Max. :174.00 Max. :77.00 Max. :108.000
dest_fnb dest_facilities dest_retail geometry
Min. : 0.0 Min. : 0.00 Min. : 0 LINESTRING :21598
1st Qu.: 0.0 1st Qu.: 0.00 1st Qu.: 0 epsg:3414 : 0
Median : 0.0 Median : 0.00 Median : 336 +proj=tmer...: 0
Mean : 53.1 Mean : 28.39 Mean : 1503
3rd Qu.: 28.0 3rd Qu.: 36.00 3rd Qu.: 1798
Max. :1275.0 Max. :429.00 Max. :16950
Since the SIM is based on Poisson Regression (this model uses log values), it is important for us to ensure that no 0 values in the explanatory variables as these will be parsed as undefined.
# save columns as a vectorupdate_cols <-c("origin_hdb", "origin_offices", "origin_schools", "dest_hdb", "dest_entertn", "dest_fnb", "dest_facilities", "dest_retail")# update all 0 values across columnsflow_attr <- flow_attr %>%mutate(across(all_of(update_cols), ~ifelse(. ==0, 0.9, .)))summary(flow_attr)
origin_hex dest_hex trips trips_quantile
237 : 151 320 : 151 Min. : 1.0 < 50 :6373
320 : 151 353 : 151 1st Qu.: 36.0 100 ~ 250 :3644
353 : 151 436 : 151 Median : 161.0 1000 ~ 5000:3121
436 : 151 534 : 151 Mean : 945.7 250 ~ 500 :2762
534 : 151 637 : 151 3rd Qu.: 648.8 < 100 :2518
637 : 151 648 : 151 Max. :63626.0 500 ~ 1000 :2213
(Other):20692 (Other):20692 (Other) : 967
flowNoIntra offset distance origin_hdb
Min. : 1.0 Min. :1 Min. : 750 Min. : 0.90
1st Qu.: 36.0 1st Qu.:1 1st Qu.: 6495 1st Qu.: 0.90
Median : 161.0 Median :1 Median :10500 Median :13.00
Mean : 945.7 Mean :1 Mean :11059 Mean :19.64
3rd Qu.: 648.8 3rd Qu.:1 3rd Qu.:14981 3rd Qu.:34.00
Max. :63626.0 Max. :1 Max. :39086 Max. :77.00
origin_offices origin_schools dest_hdb dest_entertn
Min. : 0.90 Min. : 0.90 Min. : 0.90 Min. : 0.900
1st Qu.: 0.90 1st Qu.: 0.90 1st Qu.: 0.90 1st Qu.: 0.900
Median : 0.90 Median : 0.90 Median :14.00 Median : 0.900
Mean : 69.46 Mean : 23.28 Mean :19.98 Mean : 5.133
3rd Qu.: 53.00 3rd Qu.: 33.00 3rd Qu.:34.00 3rd Qu.: 0.900
Max. :2295.00 Max. :174.00 Max. :77.00 Max. :108.000
dest_fnb dest_facilities dest_retail geometry
Min. : 0.9 Min. : 0.90 Min. : 0.9 LINESTRING :21598
1st Qu.: 0.9 1st Qu.: 0.90 1st Qu.: 0.9 epsg:3414 : 0
Median : 0.9 Median : 0.90 Median : 336.0 +proj=tmer...: 0
Mean : 53.7 Mean : 28.93 Mean : 1503.5
3rd Qu.: 28.0 3rd Qu.: 36.00 3rd Qu.: 1798.0
Max. :1275.0 Max. :429.00 Max. :16950.0
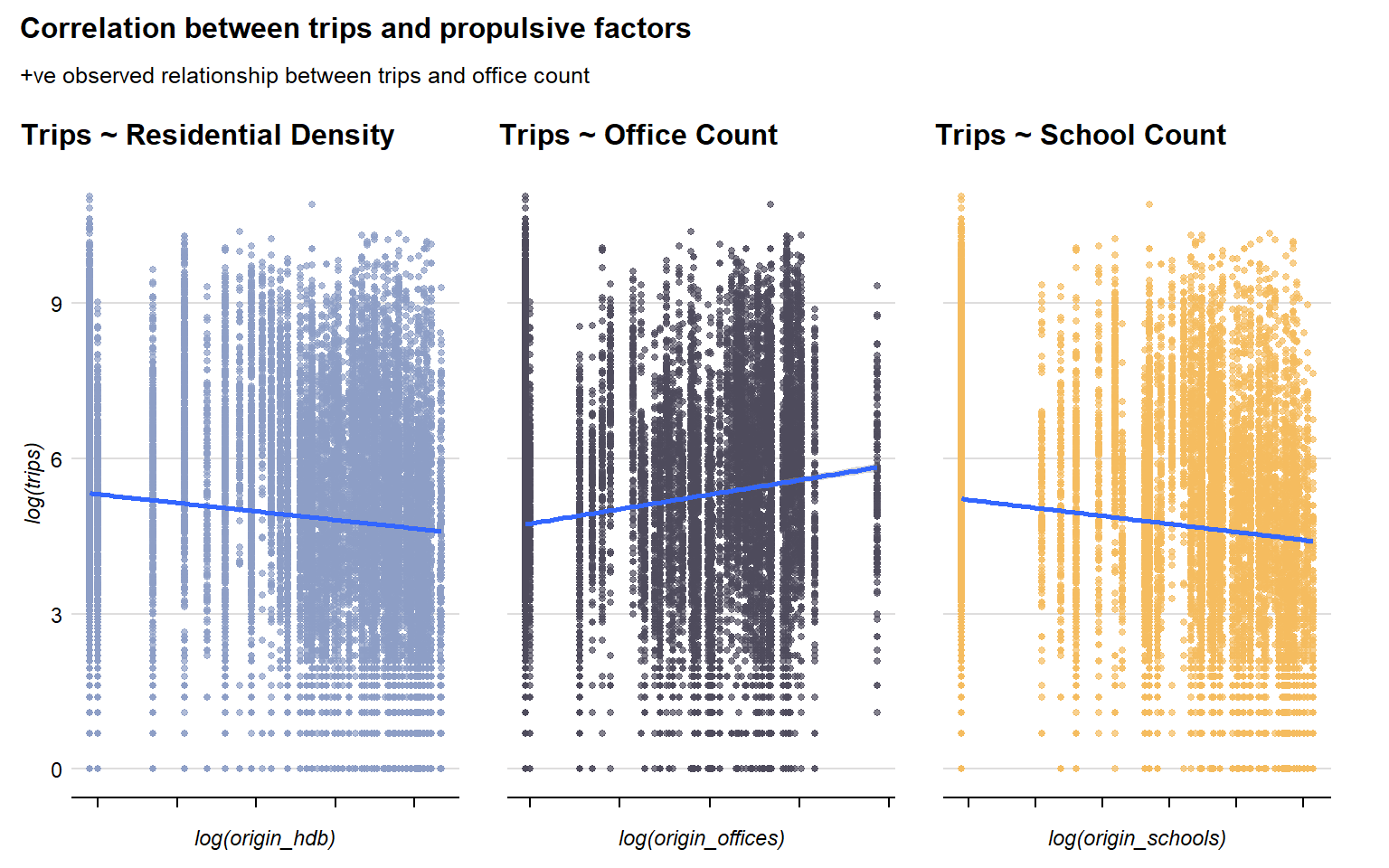
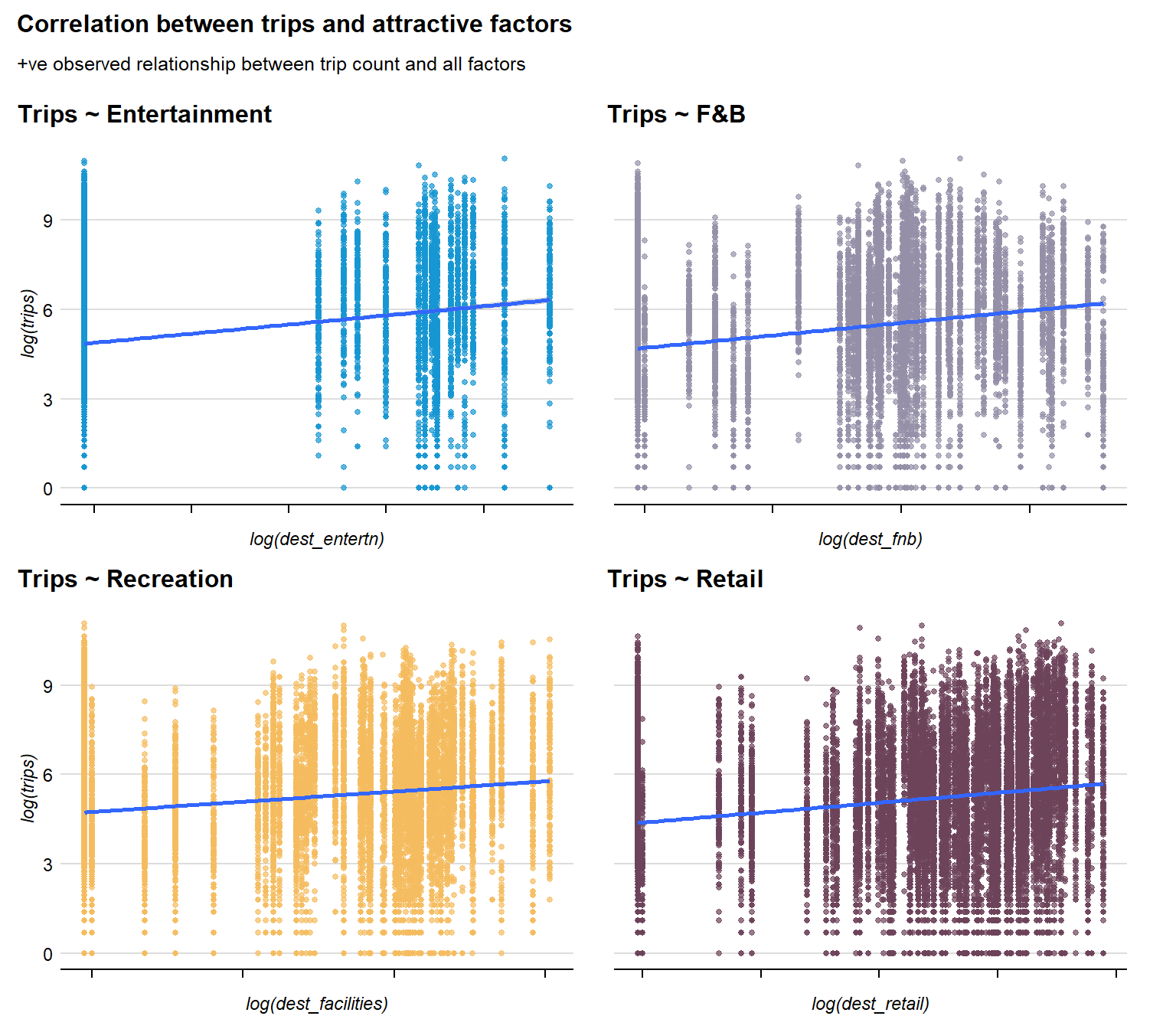
The Scatterplots above reveal that there seems to be a positive correlation between number of trips and number of offices, while there is a negative correlation between trips and residential density and school count. This could suggest that higher number of trips could be related to higher workplace concentration in the origin TAZ. Conversely, there is a similar positive correlation between number of trips and all attractive factors, indicating some relationship between higher trips towards destination areas with more leisure activities or food options. However, to understand the explanatory strength of these attributes as push or pull factors in these passenger trips, we run a series of spatial interactive models (SIMs) to estimate the likelihood or intensity of interactions between locations.
Number of weekday evening peak period trips has a statistically significant relationship with all destination attractiveness attributes
The strongest +ve association is with number of HDB blocks (Coefficient Estimate: 0.1906171) followed by entertainment venues (Coefficient Estimate: 0.1394649). This suggests that the most attractive factors are housing and available entertainment centres such as cinemas and theaters
On the other hand, the strongest -ve association is with distance (-0.7006256). This reveals that the further away the destination, the less attractive it is.
Weekday evening peak period trips has a statistically significant relationship with all origin propulsive attributes
As with the origin-constrained model, the strongest -ve association is with distance (-0.7982436), asserting that as distance increases, the number of trips decreases.
Pervasiveness of offices and schools have +ve correlations to number of trips, while more residential properties recorded -ve correlation – this suggests that there is a higher propulsion to leave the origin from work or school rather than home.
6.5Doubly-constrained SIM
This is an extension of the basic spatial interaction model that introduces constraints on both the origins and destinations of flows.
The difference between null deviance and residual deviance is substantial, suggesting that the model predictor variable (distance) provides valuable information in explaining the variability in number of weekday evening peak hour train trips
This is substantiated by the origin and destination constrained model results, where higher number of trips are related to decreasing distances.
6.6Model Diagnostics- R-squared
The goodness-of-fit test using \(R^2\) values is used to evaluate how well the models explain variations in number of O-D trips.
The \(R^2\) Values for each model are summarized below:
SIM
\(R^2\)
Origin-constrained
0.275
Destination-constrained
0.251
Doubly-constrained
0.615
We see that there is a marked improvement in \(R^2\) value in the doubly-constrained SIM compared to other singluar constrained models. This means that it accounts for ~62% of variation in number of trips. .
6.7Model Diagnostics- RMSE
Root Mean Squared Error (RMSE) is a measure of RMSE how spread out the residuals (prediction errors) are – in general, it tells us how concentrated the data is around the line of best fit. A better fitting model thus has a lower RMSE score.
The following steps are taken to compute the RMSE for all models for comparison:
compare_performance9) function computes the RMSE score for all models:
compare_performance(all_models,metrics ="RMSE")
# Comparison of Model Performance Indices
Name | Model | RMSE
------------------------------------------
origin_constrained | glm | 2238.430
destination_constrained | glm | 2266.699
doubly_constrained | glm | 1624.140
The model comparison reveals that the doubly constrained model has the lowest RMSE score, and is the best fitting model out of all 3 SIMs. This result is consistent with the earlier \(R^2\) comparison, thus strongly positioning the doubly-constrained model as the best fit model.
6.8Model Diagnostics - Fitted vs Observed values
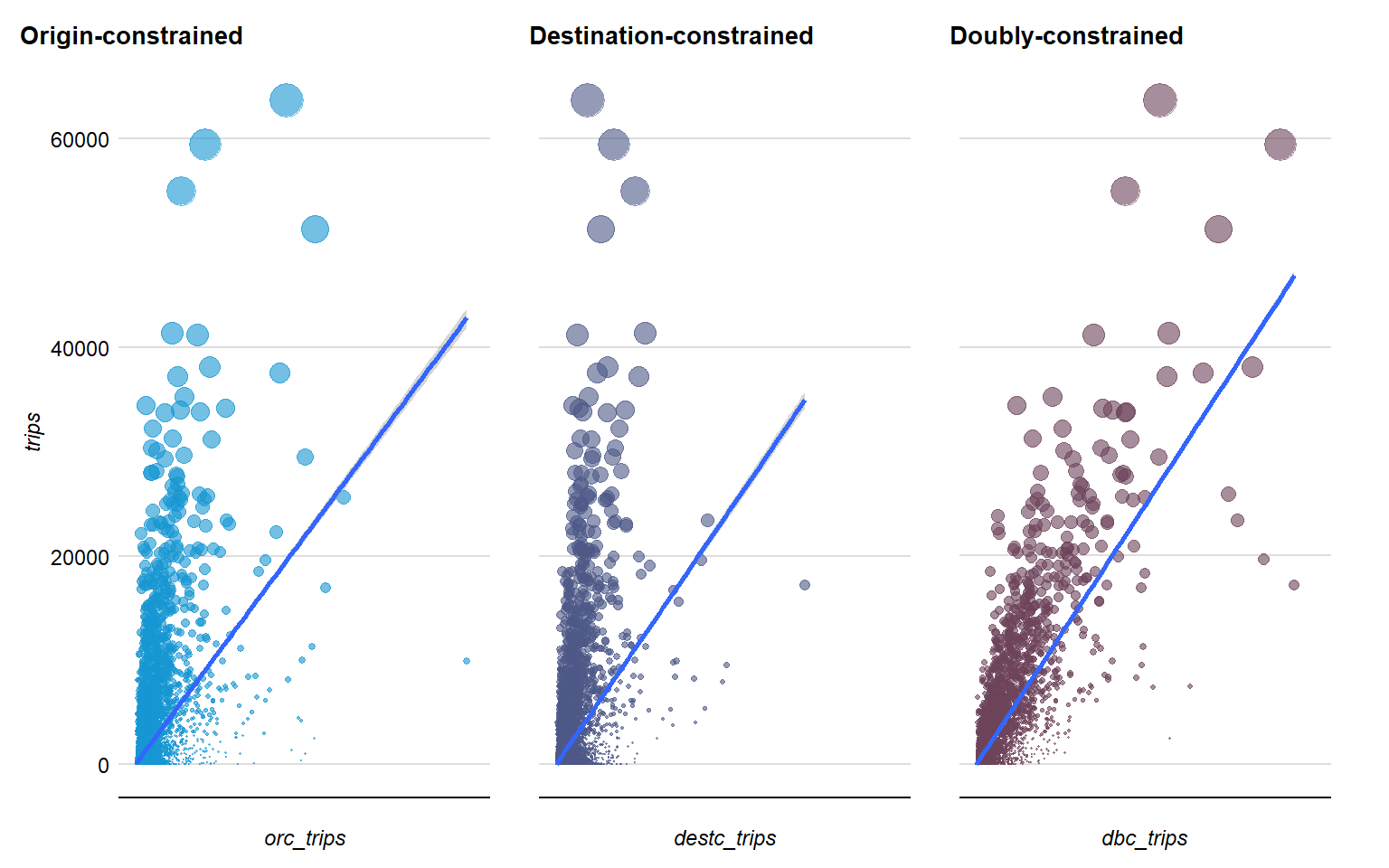
Plotting the model’s fitted versus observed values could provide insights into the spread and linearity of the model; in general, a well-fitted model would exhibit a tight and linear relationship between the fitted and observed values. A scattered or non-linear pattern, on the other hand, may indicate that the model does not capture the underlying structure of the data.
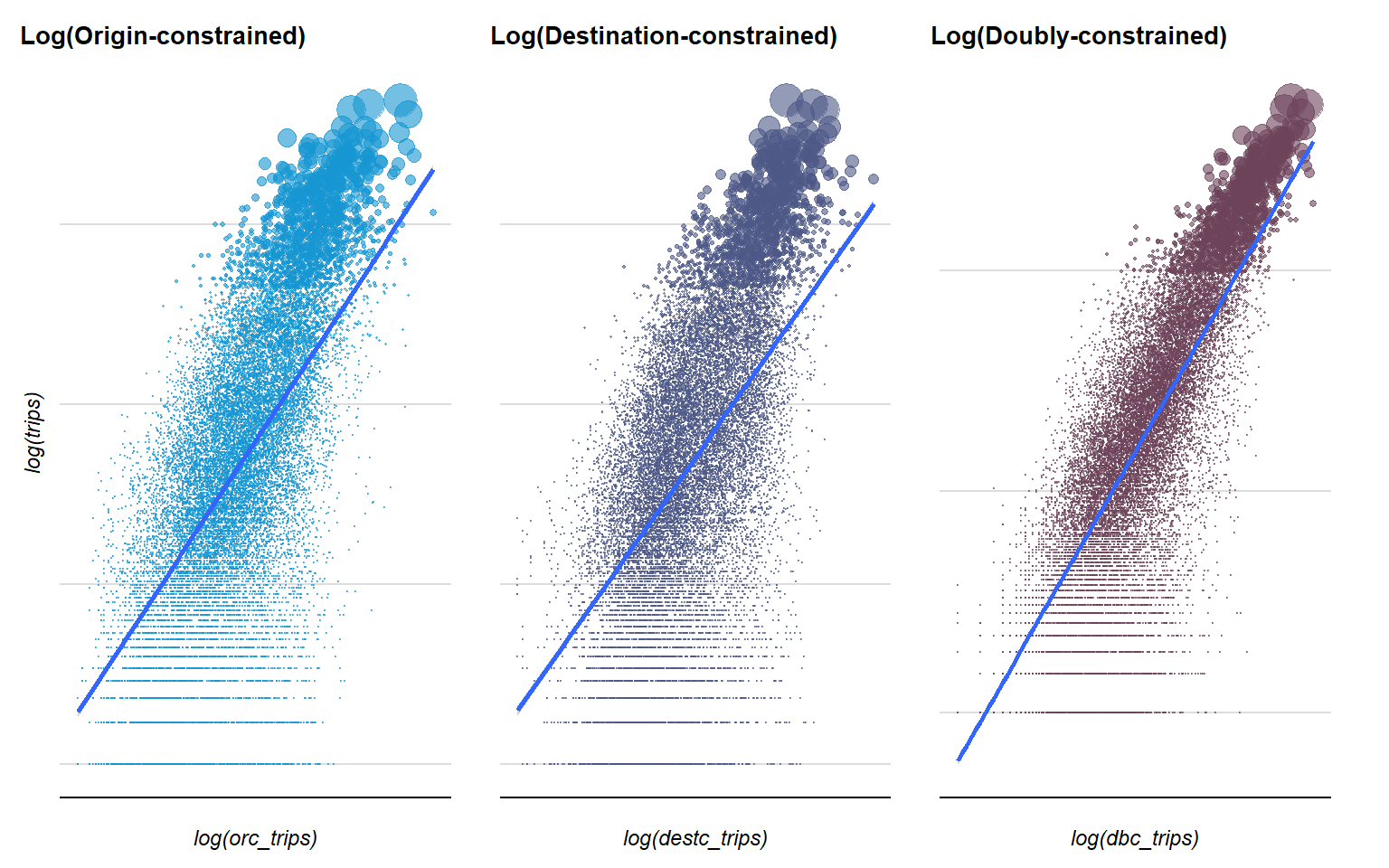
The scatterplots with original values above show that there is a stronger linear trend between fitted and observed values in the doubly-constrained model, compared to the deviation of points in the origin-constrained and destination-constrained models. However, due to the skewed nature of the distribution of trips, this may result in disproprotional or unmeaningful conclusions. To stabilize the variance of the data scales, we look at log transformed fitted versus observed trip values instead.
The log-transformed scatterplots provide increased interpretability of the values – The doubly-constrained model still seems to have a closer linear relationship, while the points in the origin-constrained and destination-constrained models only taper off from the linear trend towards the top.
7Key Takeaways from Study
From the Goodness-of-fit and Linearity tests conducted, the doubly constrained SIM consistently outperformed origin-constrained and destination-constrained SIMs. This suggests that:
The simplicity of the model is effective in capturing underlying patterns in the data. Despite having fewer variables compared to the other two models, the doubly-constrained SIM achieved better performance – thus indicating that the additional complexity of the other models may not necessarily improve the explanatory power of the models.
Distance between TAZs is thus the key explanatory variable influencing number of trips during Weekday Evening Peak Periods, where shorter distances tend to lead to higher number of trips. Even in the origin and destination-constrained models, distance had the highest negative association (around -0.79); this figure represents the effect of a unit of increase in distance on the expected number of trips. When we compare the top 10 trips by distance versus number of trips below, we see that the most frequent trips by passenger volume are ~10 times shorter in distance than the least popular trips:
Most popular trips recorded an average distance of ~3500m
However, it is not indicative that the origin-constrained and destination-constrained SIMs are not valid, or that other variables have no explanatory value. There is a need for further calibration of the model, such as including data from a longer time-range sample (over 6 months)
The explanatory variables used for the SIMs are related to the quantity of specific types of facilities within each TAZ, but does not account for the quality of these features. More qualitative data such as types of shops in retail areas or popularity of F&B joints could be considered as other factors
Spatial Interaction Models assume independence among observations in each TAZ, and does not consider the relative attractiveness or propulsiveness of the neighbouring areas. Further spatial econometrics modifications could be made to the SIMs by adding weighted metrics to understand the relative influence of the neighborhood on the TAZs.